다층 퍼셉트론(MLP)
-선형 데이터 세트: 데이터를 하나의 직선으로 분류할 수 있음
-비선형 데이터셋: 데이터를 직선으로 분류할 수 없으며 두 개 이상의 직선이 필요함
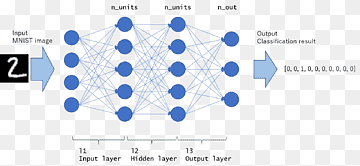
FC(완전 연결 계층)
-이전 레이어의 모든 노드는 다음 레이어의 모든 노드에 연결됩니다. 이렇게 구성된 신경망을 완전 연결망(Fully Connected Network)이라고 합니다. 노드와 노드를 연결하는 간선은 해당 노드 출력의 중요도를 나타내는 가중치입니다.
정리하다
숨겨진 계층의 수: 숨겨진 계층의 수와 숨겨진 계층의 뉴런 수는 임의로 늘릴 수 있으며 뉴런의 수가 많을수록 학습률이 높아집니다. 그러나 뉴런이 너무 많으면 훈련 데이터에서는 좋은 성능을 보이지만 새로운 데이터에서는 정확도가 떨어지는 과대적합이 발생합니다.
활성화 기능: 여러 유형이 있습니다. (ReLU, 소프트맥스.. 등..)
오류 함수: 신경망의 예측 결과가 실제 레이블 값에서 얼마나 벗어났는지를 측정하는 함수입니다. MSE(평균 제곱 오차)는 주로 회귀 문제에 사용되며 (교차 엔트로피) 분류 문제에 사용됩니다.
최적화 기법: 최적화 알고리즘은 오류를 최소화하는 가중치를 찾는 역할을 합니다. BGD, SGD Adam, RMSprop 등이 있습니다.
배치 크기: 매개변수가 업데이트될 때마다 신경망에 공급되는 훈련 데이터의 양을 나타냅니다. 배치 크기가 클수록 학습 시간이 빨라지지만 더 많은 메모리가 필요합니다. 기본값인 32~64,128,256으로 늘리는 것을 권장합니다.
에포크 수: 훈련 중에 총 훈련 데이터가 신경망에 공급되는 횟수를 나타냅니다. 테스트 데이터의 정확도가 감소하기 시작할 때까지 에포크 수를 점차적으로 늘립니다(과적합의 징후).
학습률: 최적화 알고리즘의 매개변수입니다. 이론적으로 학습률은 최적의 매개변수에 도달할 수 있을 만큼 작아야 하지만(무한 학습이 가능한 경우) 학습률이 클수록 학습률이 빨라지고 최적의 매개변수에 도달하지 못할 확률이 높아집니다.